For Developers
For LLMs
The API for
multi-document processing
Turn documents into a single structured response.
Cross-document entity linking, contradiction detection, bounding boxes and UI toolkit to show it all included.
Who This Is For
Level up your pipeline, agent, or manual process
How Parsewise Compares
Single-doc parsers and RAG solve are limited in their scope.
Parsewise goes beyond: cross-document reasoning with full traceability and no false negatives.
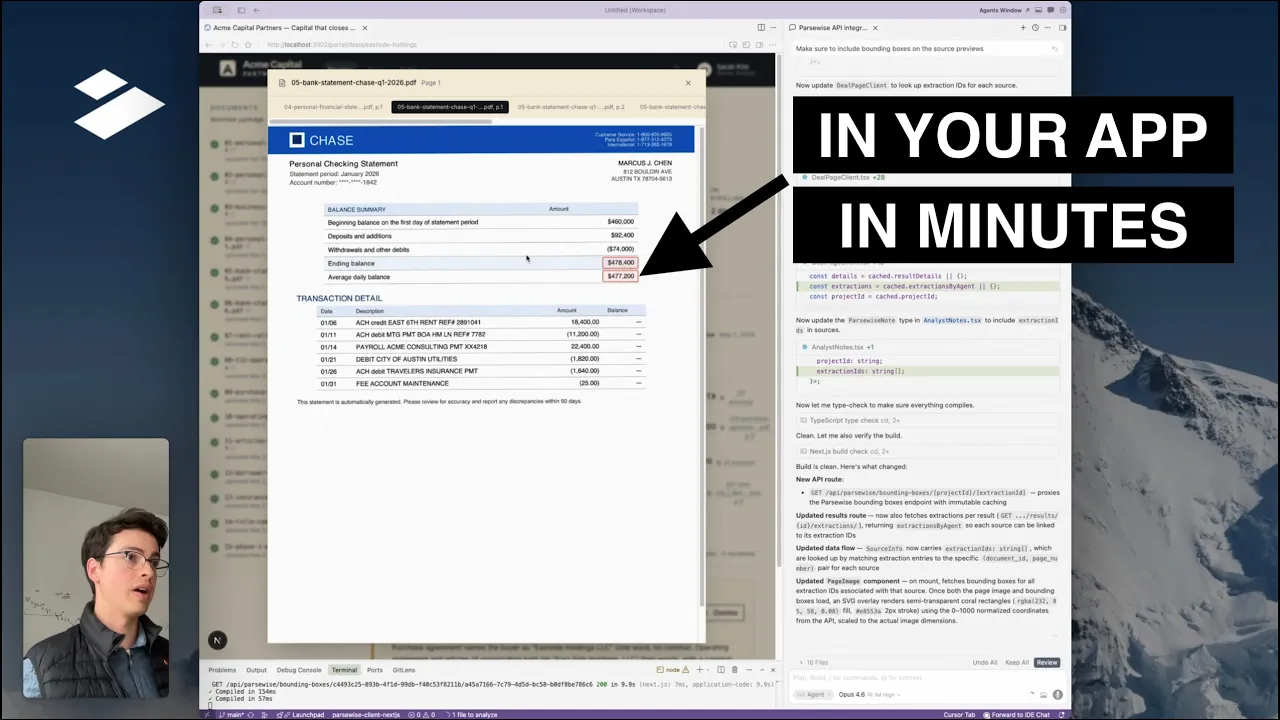
Built with Claude on Parsewise
Build a multi-document pipeline in 1 minute
Why Parsewise
Exhaustive. Not approximate.
How Builders Use Parsewise
Live with

Submission Triage at Scale
Live with

Live with

Beyond Structured JSON
The API is just the start.
Parsewise provides the full toolkit to configure, consume, verify, and iterate.

FAQ
Why not Textract / Reducto / Azure Doc Intelligence + Claude Code?
Those are excellent for per-document extraction. You still have to write and maintain the layer that reconciles, links, and resolves contradictions across an entire corpus. That layer is Parsewise.
Why not just use an LLM API with structured outputs?
You can't fit a real corpus in one call, cost scales linearly per document, outputs are non-deterministic, and there's no native entity linking across calls. Orchestration is the hard part, and it's not what you should be building.
Why not RAG?
RAG is built for chat-style retrieval over big corpora, not for maximum quality, full traceability, and zero false negatives. Top-K silently drops the long tail. Numeric and tabular values get lost in embedding noise. Wrong tool for risk-grade decisions.
Why not Claude Code or other agentic tools?
Grepping through documents leads to false negatives, and deep agent-driven analysis is slow and expensive at corpus scale. Parsewise gives you deterministic, traceable, schema-shaped output instead of a chat transcript.
Why not build it ourselves?
Same reason you're not building Excel. Unless multi-document resolution is your core product, you want to ship into your niche, not vibe-code and vibe-debug a bespoke pipeline that breaks every time business rules change. We wrote a full guide on what it takes to build and operate a document processing pipeline in-house.
Move from reactive large-loss management to proactive severity control.
The future of risk decisions, today. Submit your email and we'll reach out.