The Enterprise Layer
for Unstructured Documents
The way business users work with unstructured documents has not changed for decades.
Parsewise develops the core technology that enables exhaustive, self-learning document processing
over long time horizons, designed for real enterprise workloads.
Parsewise Data Engine (PDE)
PDE is built around a structured world model: a persistent, structured
representation of everything known about the task and information available.
The result is document intelligence that does not go off the rails
when scale or complexity increases.


Key Developments
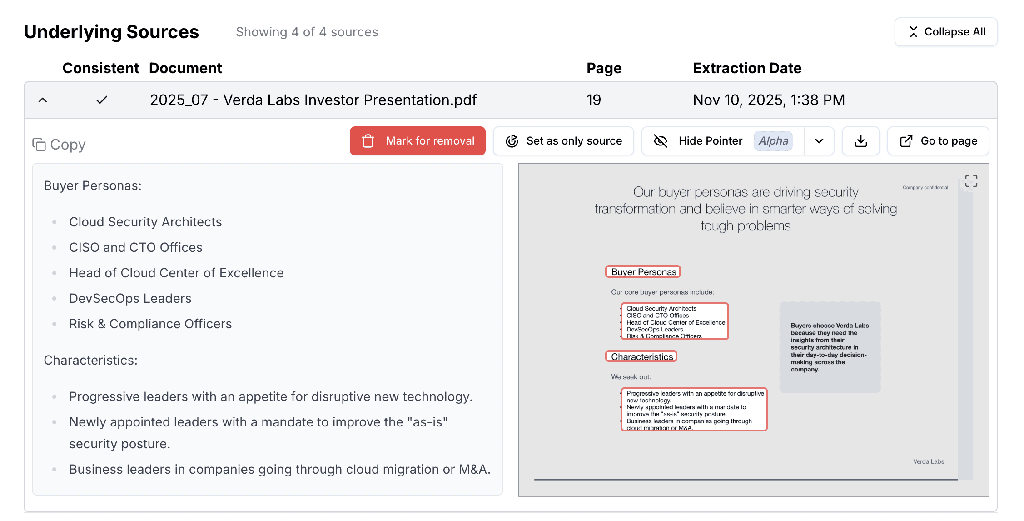
Cross-Document Attention
Modeling relationships across an entire document corpus simultaneously.
- Capture links, contradictions, and dependencies across entire corpora
- Eliminate hallucinations by grounding outputs in all relevant sources
- Never miss edge cases hidden outside retrieved snippets
RL from User Interactions
Continuous learning system that adapts to real context.
- Trains policies directly from real user behavior, not synthetic proxies
- Captures domain-specific preferences that static models miss
- Continuously improves relevance, judgment, and workflow fit
Enterprise Scalability
Production-grade infrastructure for very large document packages.
- Processes hundreds of thousands of pages per run with predictable SLAs
- Elastic orchestration, queuing, and retries for spiky workloads
- Central monitoring, audit, and versioning across projects
KPI-Specific Models
Precision models tuned and validated for business KPIs.
- Built for narrow, high-value tasks using targeted fine-tuning
- Outperform general models on structure, accuracy, and edge-case handling
- Capture domain logic from real documents and user habits
Automated Ontology Generation
Business-ready structure without engineers.
- Generates and updates domain ontologies through natural interaction
- Removes technical barriers, enabling teams to adapt structure
- Integrates cleanly with existing databases and enterprise systems
Join us!
If you have world-class experience in any of the above areas or adjacent fields, please reach out. We are always hiring exception engineers!